Why the London of British Literature Barely Changed for 200 Years
An innovative mapping project uncovers just how limited the literary version of the city has often been.

Erik Steiner is a geographer, and in his field people trying to understand how places worked in the past tend to look at census records and old maps. But in a recent project, Steiner, the creative director of Stanford University’s Spatial History Project, worked with colleagues from the school’s Literary Lab to mine an unusual source of geographical data: 4,862 works of British literature, published between 1700 and 1900.
“From a geographer’s standpoint, fictional geography is amazing,” he says. Characters in novels are often moving about real places, recruited as settings because they’re recognizable to readers. Even in creating a fictional world, novelists are capturing data about the reality in which they live. Pull out that data, says Steiner, and “you can uncover some unexplored truth that’s somewhere in there.”
In the case of London, one of the team’s discoveries, published in a pamphlet this past fall, was that the physical London of the 19th century and the fictional London of the same time period occupied two different geographic spaces. Even as physical London expanded madly, fictional London stayed small, contained within the historic city center and the wealthy West End.
“From the perspective of literature, London’s urban development didn’t quite happen,” says Ryan Heuser, a Stanford graduate student who led the Literary Lab’s research on the project.
Literary geography is a relatively new field of study: the 1998 Atlas of the European Novel, written by Stanford’s Franco Moretti, a collaborator of Heuser and Steiner on the London project, is considered one of the discipline’s first modern works. The goal, as a group of European cartographers wrote in 2008, is to explore “what happens when the ‘literary world’ and the real world meet or intersect.”
The London project drew on even newer strategies of “digital literary geography,” using algorithms and other digital tools to explore place in British literature. It was developed under the umbrella of Stanford’s Center for Spatial and Textual Analysis, by a team that included several undergraduate research assistants, along with grant and project managers. They identified hundreds of historical locations in London, by matching proper names from their corpus of texts to historical maps and other sources. Altogether, those names appeared in about 15,000 passages over thousands of texts.
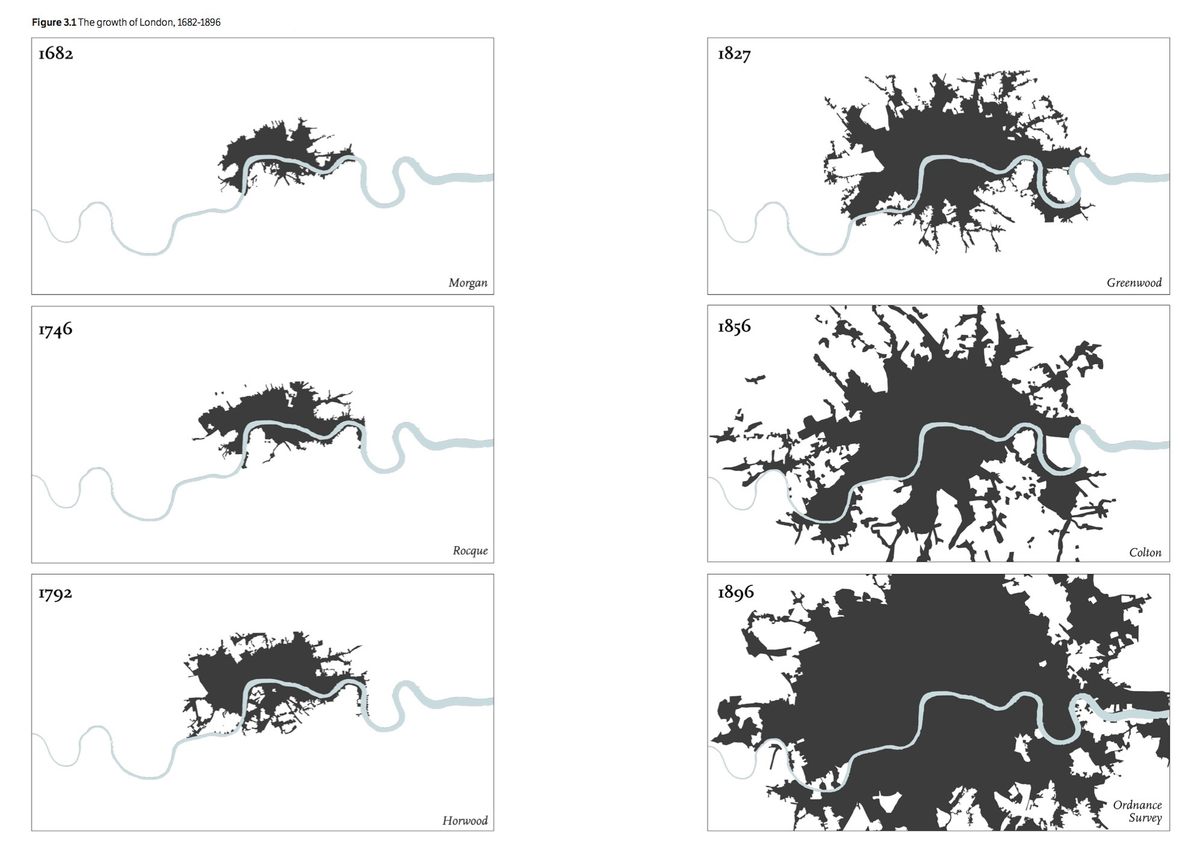
With that data set in hand, the researchers worked to map literary London. Using historic maps and census records, Steiner created a series of images (above) showing the growing urban density in real-world 1682 London, when it was a small city huddled along the banks of the Thames, to 1896 London, when its population was heading toward 6.5 million people.
On top of those maps of urban growth, the team layered the places mentioned in their texts, to show how literary London developed alongside real-world London. Literary London, they found, changed hardly at all: even as real-world London grew, literature stayed put in the historic center of the city and in the wealthy West End.
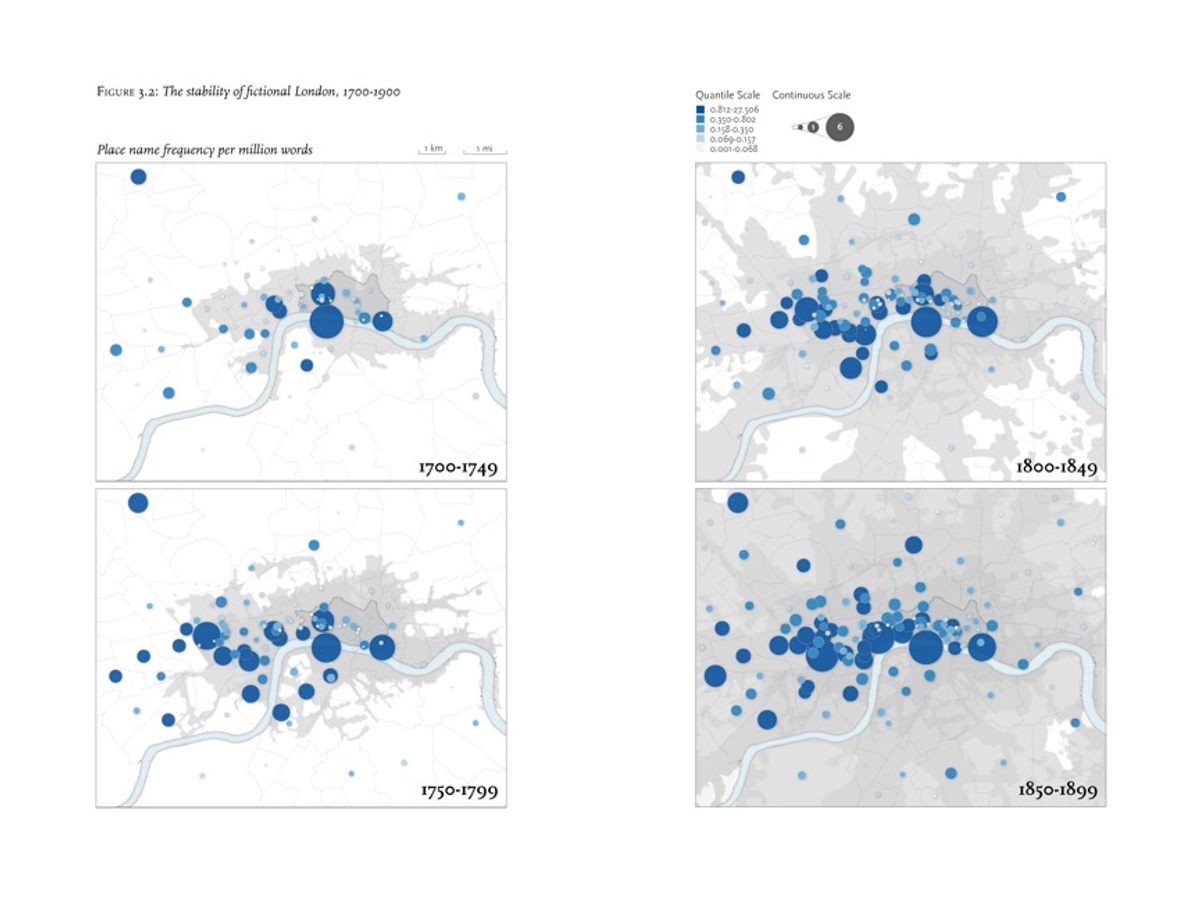
“The number of geographical references kept increasing, but they remain essentially localized in the City and in the West End,” the researchers write in the pamphlet. “The rest of London—where most of the growth was actually taking place—never really mattered. In the course of the nineteenth century, real London radically changed—and fictional London hardly at all.”
Literary London had, in Heuser’s words, a “historical stuckness” that restricted its growth. Even as the city grew, the places that authors used as touch points, to imbue their stories with meaning, stayed the same.
The Stanford researchers weren’t just interested in locating literary London, though. They wanted to map the emotions of the literary texts onto the city—the relationship between space and emotion and how that’s reflected in literature.
It’s not intuitive to think that emotions might have a location. Where is sadness? Where is happiness? Do emotions have, the researchers asked, “an intrinsic connection to a specific place”? Inspired by a passage about the “element of suddenness” in fear, the Stanford researchers saw a way to link emotion with place: the suddenness of emotion could tie it to geography. “What is sudden occurs at a specific moment in time and hence also at a specific point in space,” they write.
To create a data set of place and emotion, the Stanford team clipped 200-word passages, centered around place names, and had 20 people read each passage. Half were asked to judge if the passage had an element of fear to it; the other half were asked to note if it had an element of happiness. The researchers also ran the passages through an algorithm that identified sentiment.
Their baseline finding was surprising: the majority of the passages—two-thirds, according to the human readers—were emotionally neutral. The passages that had an emotional valence, though, did have some relationship to place. With another group of colleagues, Heuser mapped the emotion data onto an 1899 map of London that included sociological data on class and poverty.
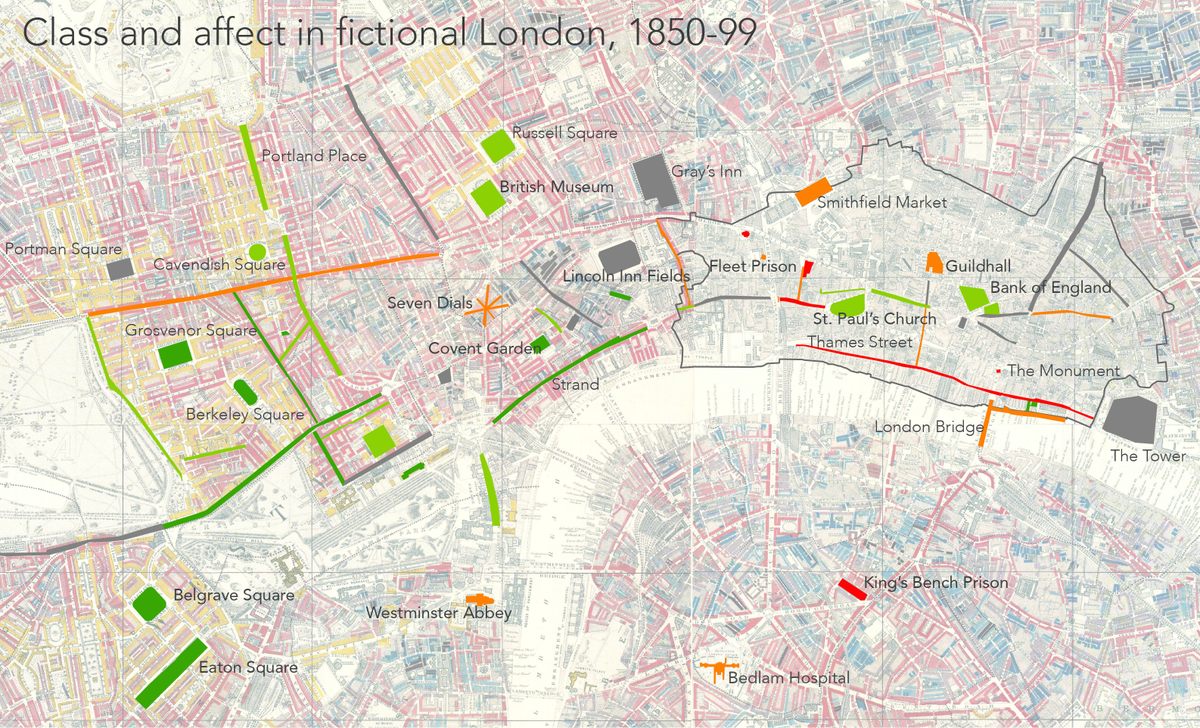
In that context, he could see how passages with positive emotions were associated with the West End and other wealthy places, while passages with negative emotions tended to be embedded in neighborhoods the 1899 map coded as “struggling.”
Emotions such as fear and happiness might seem subjective and individualistic, says Heuser. But find a way to map them onto real places, and you suddenly see how very constrained they could be by economic and class geography. To him, that’s one of the great advantages of digital literary geography. Computer analysis might obscure the details of individual passages, but in exchange it offers scale. “You can do this for 5,000 novels across 200 years and draw these very large historical conclusions,” says Heuser. In fiction, at least, the places where stories take place and the places where people are allowed to feel happy are limited.












Follow us on Twitter to get the latest on the world's hidden wonders.
Like us on Facebook to get the latest on the world's hidden wonders.
Follow us on Twitter Like us on Facebook